reader 3.9 released – update hook error handling
August 2023 ∙ three minute read ∙
Hi there!
I'm happy to announce version 3.9 of reader, a Python feed reader library.
What's new? #
Here are the highlights since reader 3.7.
Better handling of unexpected update errors #
Unexpected exceptions raised by update hooks, retrievers, and parsers are now wrapped in UpdateError, so errors for one feed don't prevent others from being updated. Also, hooks that run after a feed is updated are all run, regardless of individual failures. Plugins should benefit most from the improved fault isolation.
Exception hierarchy diagram #
The API docs got a cool new exception hierarchy diagram (yes, it's autogenerated):
ReaderError
├── ReaderWarning [UserWarning]
├── ResourceNotFoundError
├── FeedError
│ ├── FeedExistsError
│ ├── FeedNotFoundError [ResourceNotFoundError]
│ └── InvalidFeedURLError [ValueError]
├── EntryError
│ ├── EntryExistsError
│ └── EntryNotFoundError [ResourceNotFoundError]
├── UpdateError
│ ├── ParseError [FeedError, ReaderWarning]
│ └── UpdateHookError
│ ├── SingleUpdateHookError
│ └── UpdateHookErrorGroup [ExceptionGroup]
├── StorageError
├── SearchError
│ ├── SearchNotEnabledError
│ └── InvalidSearchQueryError [ValueError]
├── PluginError
│ ├── InvalidPluginError [ValueError]
│ └── PluginInitError
└── TagError
└── TagNotFoundError
Parser cleanup #
I moved all modules related to feed retrieval and parsing to reader._parser, another step towards internal API stabilization. This has also given me an opportunity to make lazy imports a bit less intrusive.
Timer experimental plugin #
There's a new timer experimental plugin to collect per-call method timings.
The web app shows them in the footer like so:

Python versions #
Python 3.9 support is no more, as foretold in the ancient murals.
For more details, see the full changelog.
That's it for now.
Want to contribute? Check out the docs and the roadmap.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
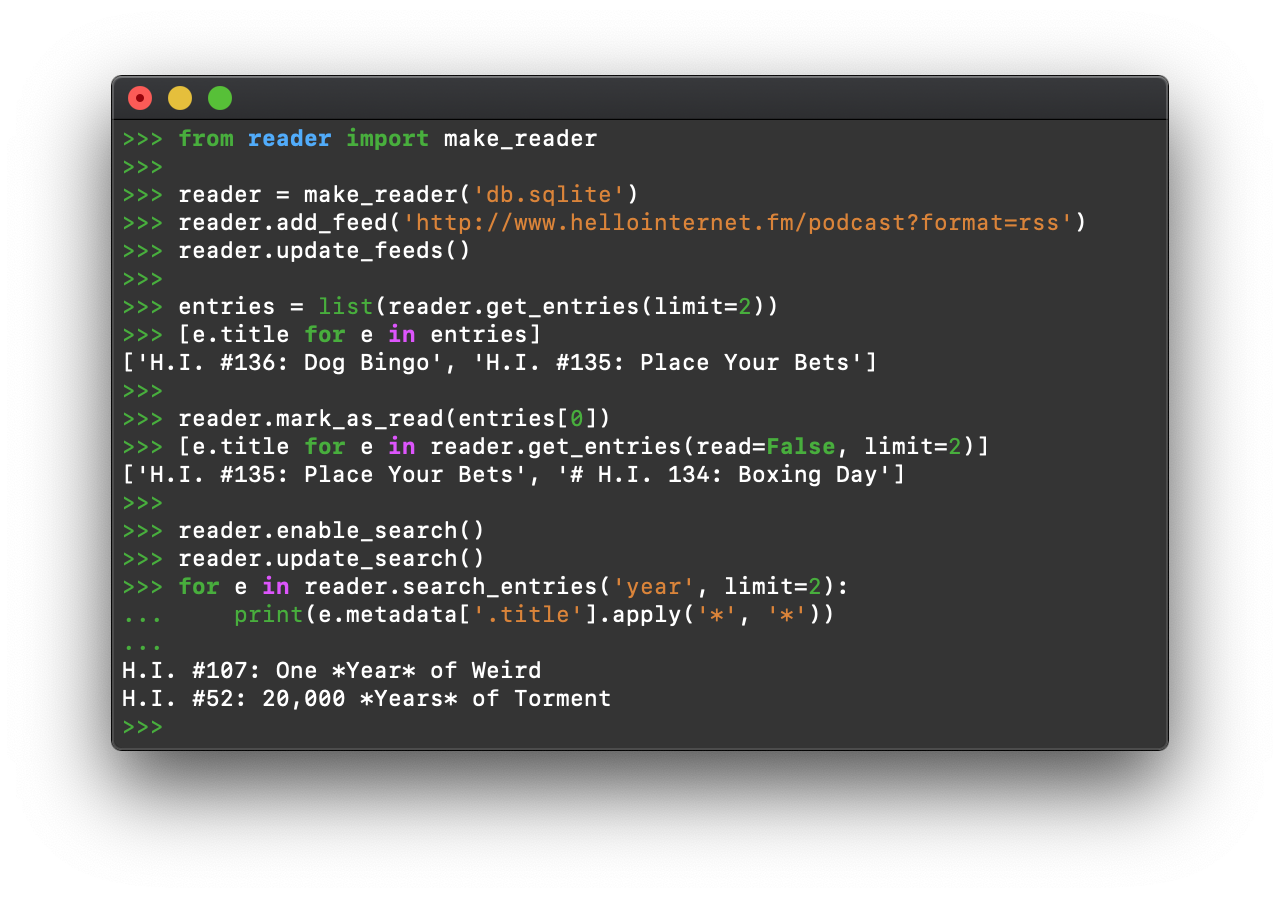 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.