reader 3.7 released – contributor docs
July 2023 ∙ three minute read ∙
Hi there!
I'm happy to announce version 3.7 of reader, a Python feed reader library.
More importantly, reader has reached 300 stars on GitHub!
What's new? #
Here are the highlights since reader 3.4.
Contributor documentation #
reader now has contributor documentation! If you want to help or you're just curious where it's all going, check out the roadmap and the reader philosophy.
Thank you to Katharine Jarmul for getting me to do this! (it only took me five years...)
Explicitly unimportant #
The important entry flag is now bool|None instead of bool,1
so there's a sane way to express "I don't care about this article".
The point of marking an article as explicitly unimportant is to give you a better understanding of how you consume content – if you consistently don't care about the articles in a feed, maybe it's time to ruthlessly Marie Kondo that crap.
Discontinued plugins #
I removed the Twitter plugin, since it's not possible to get tweets using the free API tier anymore, rendering it effectively useless. While at it, I also removed the Tumblr GDPR plugin (not needed since August 2020).
Nevertheless, they are valuable examples of how to implement reader plugins, so the docs still mention them in Discontinued plugins.
Python versions #
With PyPy 3.10 added in reader 3.7, this is the last release to support Python 3.9.
For more details, see the full changelog.
That's it for now.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
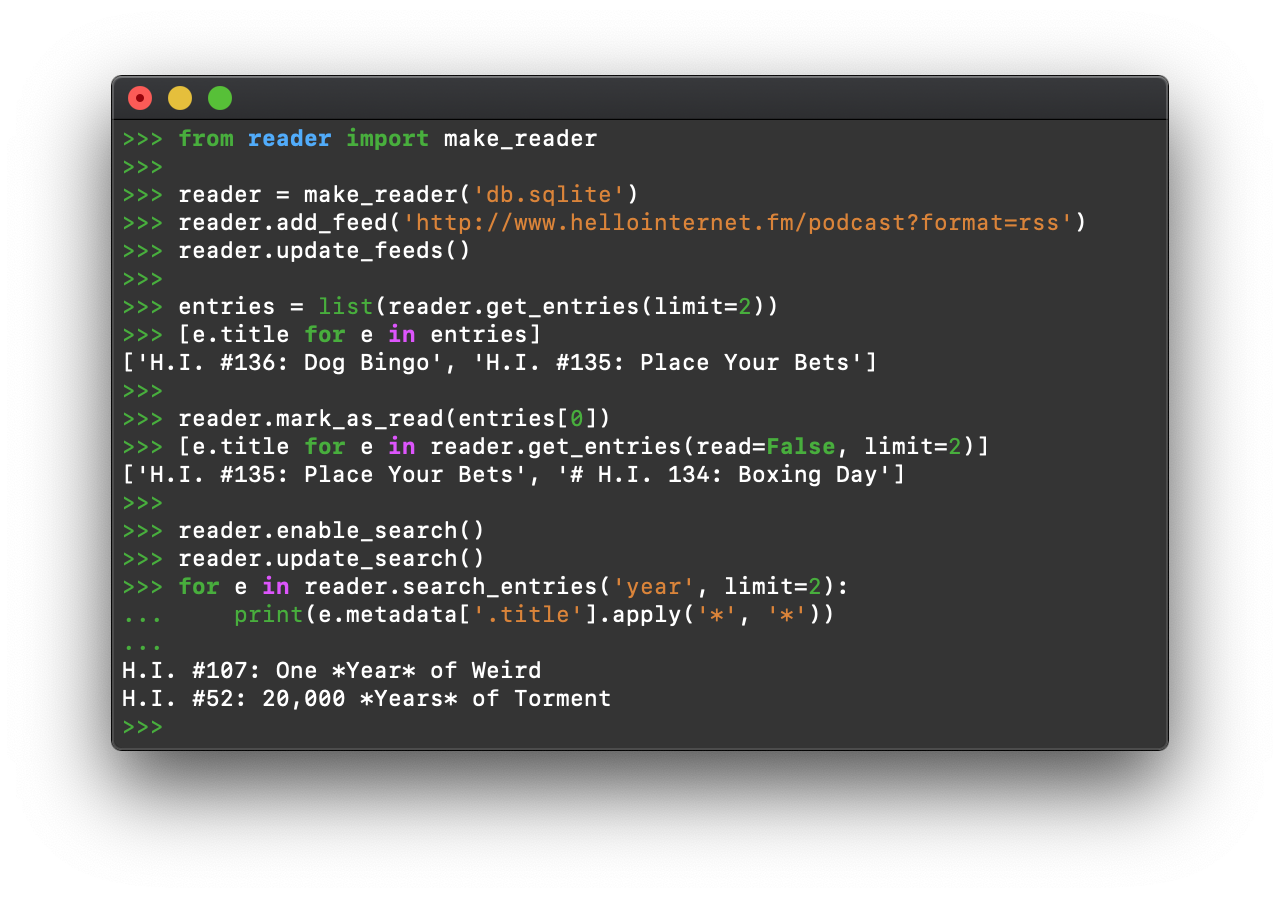 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.
By the way, I'm quite pleased with how I managed to do it in an (almost) backwards-compatible way. [return]