reader 3.4 released – 5 years, 2000 commits
January 2023 ∙ four minute read ∙
Hi there!
I'm happy to announce version 3.4 of reader, a Python feed reader library.
More importantly, reader is now 5 years old!
5 years, 2000 commits #
3.3, released in December, marks reader's 5th anniversary and its 2000th commit.
I don't really know what to say, so I'll just say something that maybe will help others.
I'm happy about reader. But more than that, I'm proud of it growing into what it is.
reader started as a hobby and learning project, scratch-your-own-itch kind of thing. Starting off, I had two goals: it should be a library, and it should be for the long term.1
It continued beyond that, into an experiment.
First, on applying Pieter Hintjens' problem-solution approach, and the ideas in the Write code that is easy to delete, not easy to extend and Repeat yourself, do more than one thing, and rewrite everything essays by tef of programming is terrible.
Second, and more mundane, it was an exercise in how testing and type checking keep code maintainable over time. "Everyone knows" they are good things™, but most jobs rarely emphasize the over time part – I know mine at the time didn't. I wanted a place where I could get an intuitive feel for it.
(If you'd like to read more about any of the above, do let me know.)
Judging the success of either is probably highly subjective. Nevertheless, I think they were both wildly successful. reader is still alive and kicking, despite the limited time I have for it, and I've developed habits and ways of solving problems that I'm constantly using in my professional life.
Sure, reader has flaws, and it's definitely not done (what is?), but it's the longest project I've ever worked on, and probably the best code I've ever written.
Finally, I feel I have to say that while not hugely popular, reader is way more popular than I could've dreamt 5 years ago, especially for a niche, but hopefully still relevant topic like web feeds. Thank you!
What's new? #
Here are the highlights since reader 3.0.
Parser internal API #
The parser internal API is fully documented. It continues to be unstable, but this is a huge first step on the road to internal API stabilization.
I started with the parser because it's probably most useful for plugins (for example, the Twitter plugin uses it extensively), or if you want to retrieve and/or parse feeds with reader, but handle storage and so on yourself (here's a recipe for parsing feeds retrieved with HTTPX).
Faster imports #
The time from process start to usable Reader instance is 3x shorter, by postponing update-related imports until actually needed.
Simpler entry sorting #
When sorting by recent,
newly added entries now always appear at the top,
regardless of their published date,
except on a feed's first update.
This replaces a more complicated heuristic that caused entries added to a feed months after their published (yup, that happens!) to never appear at the top (so you would never see them).
Fewer dependencies #
reader is a library, so I try to keep the number of dependencies as small as possible.
Starting with 3.1, the readtime built-in plugin has no dependencies, and it can be used even if lxml is not available (the library I was using before to calculate read time has a transitive dependency on lxml, which does not always have PyPy Windows wheels).
Python versions #
reader 3.3 adds support for Python 3.11.
reader 3.4 drops support for Python 3.8.
Bug fixes #
There were lots of bug fixes, mainly to plugins (I guess that's a good thing).
For more details, see the full changelog.
That's it for now.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
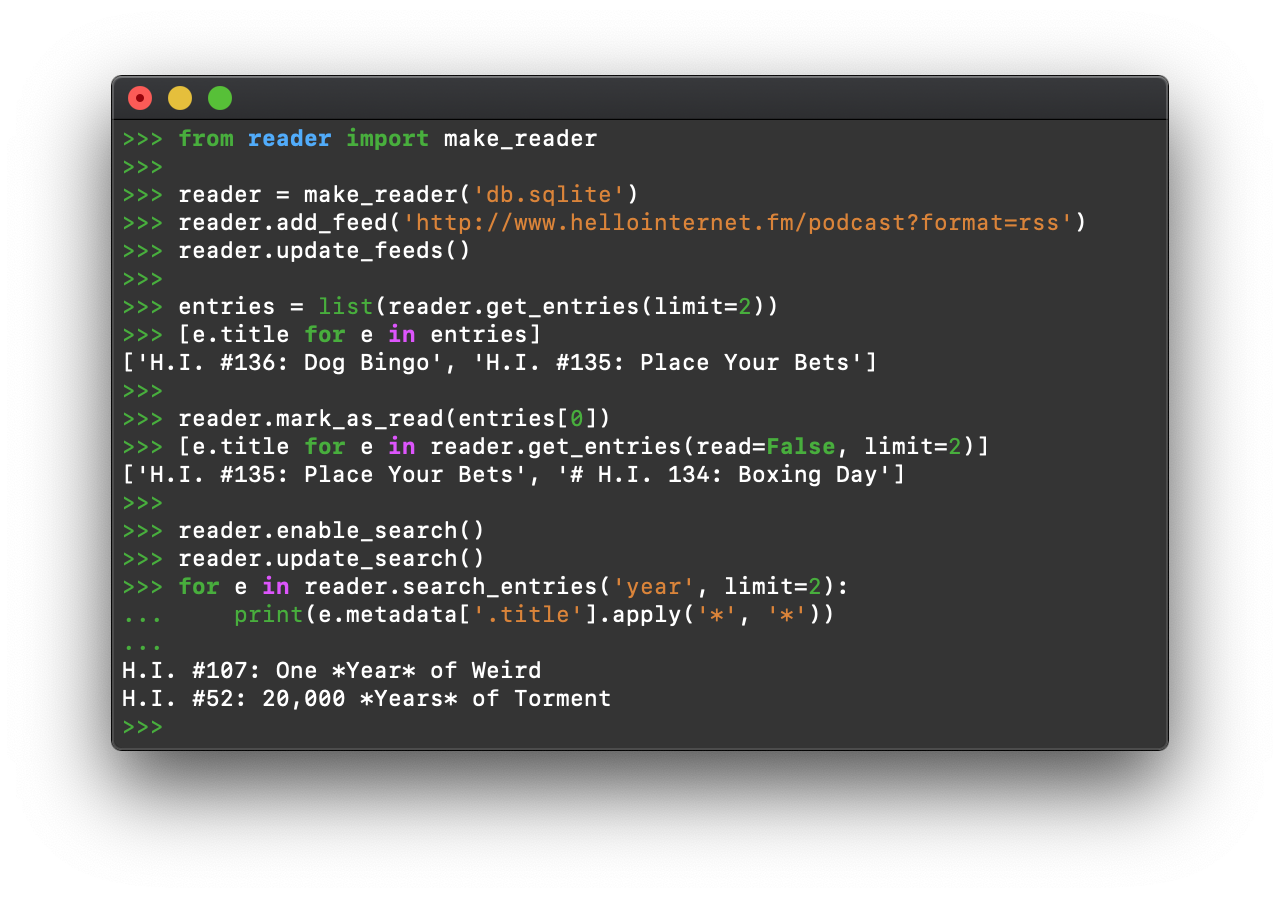 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- and even follow Twitter accounts
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to follow Twitter accounts?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.