reader 3.0 released – multithreading
September 2022 ∙ five minute read ∙
Hi there!
I'm happy to announce version 3.0 of reader, a Python feed reader library.
This release removes a number of deprecated methods and attributes, for a cleaner, more consistent API. See the changelog for details.
2.x recap #
2.0 was released over a year ago; let's have look at what happened since.
Unified tag API + entry and global tags #
Tags and metadata are now the same thing, generic resource tags:
>>> reader.get_tag(feed, 'one', 'default')
'default'
>>> reader.set_tag(feed, 'one', 'value')
>>> reader.get_tag(feed, 'one')
'value'
>>> reader.set_tag(feed, 'two')
>>> dict(reader.get_tags(feed))
{'one': 'value', 'two': None}
This means you can filter by metadata keys, and attach values to tags.
Even better, tags aren't just for feeds anymore – you can add tags to entries, and to a global namespace.
Search enabled by default #
Full-text search works out of the box: no extra dependencies, no setup needed.
Statistics #
There are now statistics on feed and user activity, to give you a better understanding of how you consume content.
First, you can get the average number of entries per day
for the last 1, 3, 12 months,
so you know how often a feed publishes new entries,
and how that changed over time –
think sparklines: 36 entries ▄▃▁ (4.0, 2.0, 0.6).
Second, reader records the time when an entry was last marked as read or important. This will allow you to see how you engage with new entries – I'm still working on how to translate this data into a useful summary.
A nice side-effect of knowing when entry flags changed is that it's possible to tell if an entry was explicitly marked as unimportant (entries are unimportant by default).
User-added entries #
You can now add entries to existing feeds. This is useful when you want to keep track of an article that is not in the feed anymore because it "fell off the end".
It can also be used to build bookmarking / read later functionality similar to that of Tiny Tiny RSS; extracting content from arbitrary pages would be pretty helpful here.
Twitter support #
You can now follow Twitter accounts (experimental, requires a Twitter account).
Read time #
The new readtime plugin calculates the entry read time during feed updates.
This makes available to any reader user a feature that was only available in the web app, and makes the web app faster.
Improved duplicate handling #
Duplicate handling got significantly better:
- False negatives are reduced by using approximate string matching and heuristics to detect truncated content.
- You can trigger entry deduplication manually,
for the existing entries of a feed
– just add the
.reader.dedupe.oncetag to the feed, and wait for the next update. Also, you can deduplicate entries by title alone, ignoring content. - Old duplicates are deleted instead of marked as read/unimportant.
Memory usage improvements #
reader update uses about 22% less memory.
The main change is not to reader itself,
but was contributed upstream to feedparser:
instead of reading the whole feed in memory to detect encoding,
use a prefix of the feed, and decode the rest on the fly.
The result is a 35% decrease in update_feeds() maximum RSS
when compared to baseline!
You can find more details here.
Multithreading #
You can now use the same Reader object from multiple threads. So, you can do stuff like this:
>>> Thread(target=reader.update_feeds).start()
Also, you can reuse Reader objects after closing.
Typing #
reader has had type annotations for most of its existence; starting with 2.14, user code can use them too.
New Python versions #
Over the course of 2.x, reader got support for Python 3.10, and PyPy 3.8 and 3.9, and dropped support for Python 3.7.
Other changes #
Aside from the changes mentioned above, a lot of convenience methods, arguments, and attributes were added. Among the more notable ones, now you can:
- filter feeds in the same way both when getting and when updating feeds – including by tags
- run arbitrary actions before and after updating feeds
That's it for now.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
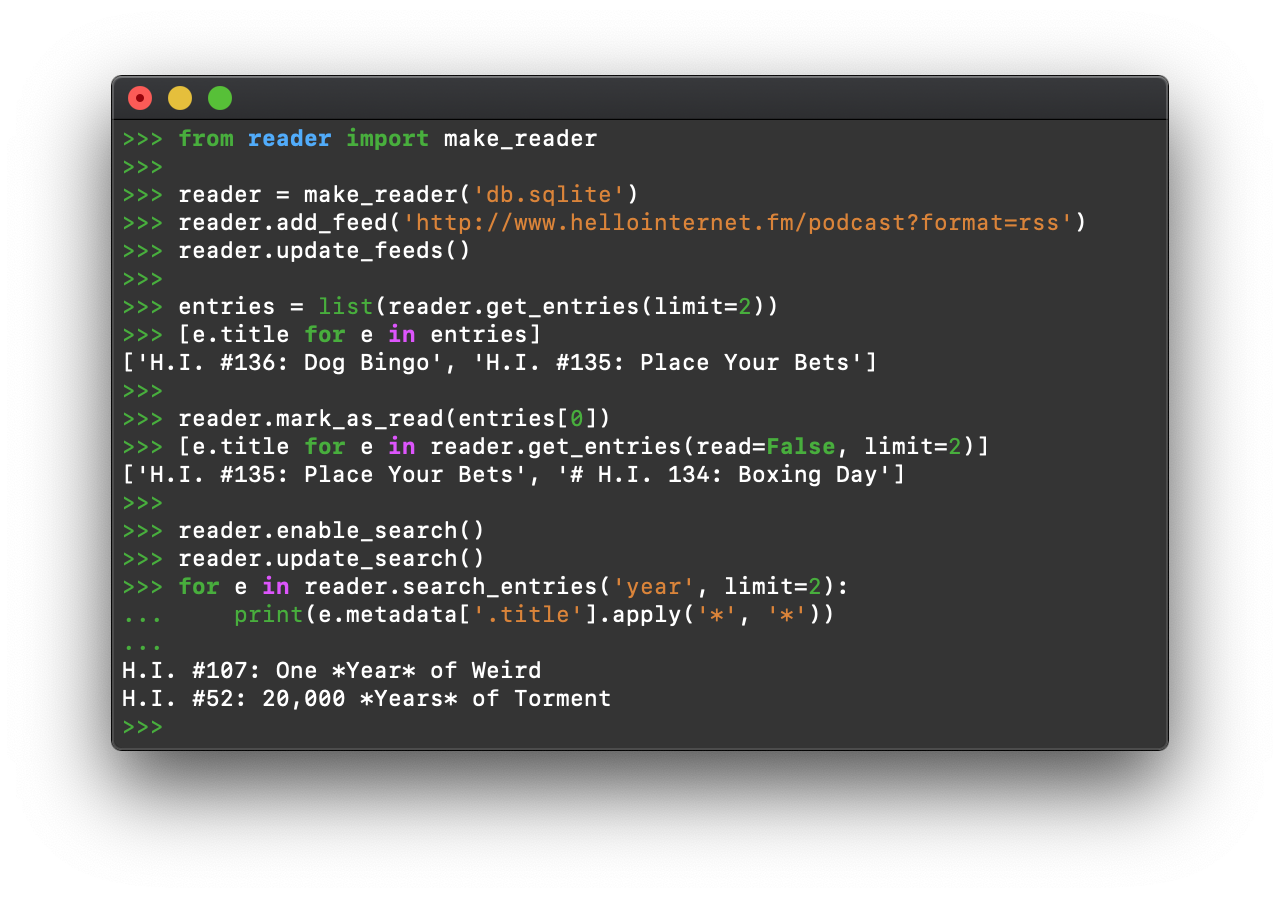 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- and even follow Twitter accounts
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to follow Twitter accounts?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.