reader 2.11 released – metadata is tags
March 2022 ∙ three minute read ∙
Hi there!
I'm happy to announce version 2.11 of reader, a Python feed reader library.
What's new? #
Quite a lot happened since reader 2.5!
Unified tag API + entry and global tags #
Tags and metadata are now the same thing, generic resource tags:
>>> reader.get_tag(feed, 'one', 'default')
'default'
>>> reader.set_tag(feed, 'one', 'value')
>>> reader.get_tag(feed, 'one')
'value'
>>> reader.set_tag(feed, 'two')
>>> dict(reader.get_tags(feed))
{'one': 'value', 'two': None}
This means you can filter by metadata keys, and attach values to tags.
Even better, tags aren't just for feeds1 anymore – you can add tags to entries, and to a global namespace.
Memory usage improvements #
reader update uses about 22% less memory, owed to two changes.
The first one is not in reader itself, but was contributed to feedparser: instead of reading the whole feed in memory to detect encoding, use a prefix of the feed, and decode the rest on the fly.2
The result is a ~20% decrease in update_feeds() maximum resident set size
(35%, when compared to baseline!).
reader will vendor the patched feedparser until the change is released upstream, so you can reap the benefits now.
The second one is parsing feeds serially, using workers only to retrieve them. Since parsing time is mostly spent in pure Python code, there's no speed-up from doing it in parallel – but each thread takes up extra memory.
This decreased update_feeds() memory usage by another ~20%
when using more than one worker
(but only on Linux; on macOS it's less notable).
Bug fixes #
The way reader checked SQLite has JSON support was somewhat brittle, causing it to fail on SQLite 3.38; reader 2.11 fixes this.
Usability improvements #
Among a number of smaller API improvements, now you can:
- filter feeds in the same way both when getting and when updating feeds – including by tags
- run arbitrary actions before updating a feed
- add an existing feed without getting an exception
- delete a missing feed or entry without getting an exception
For more details, see the full changelog.
That's it for now.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
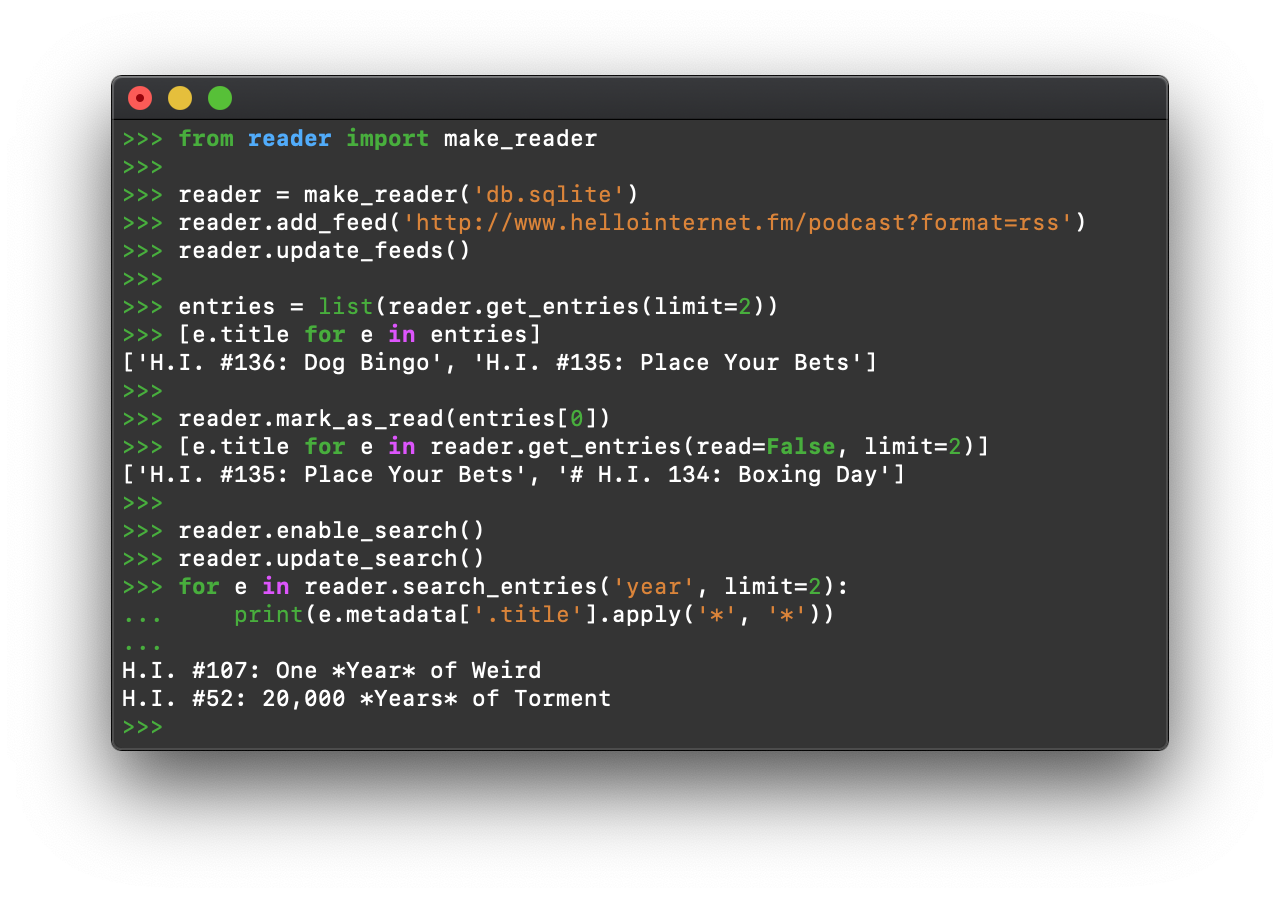 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.
The old feed-specific tag and metadata methods are still available, but are deprecated and will be removed in version 3.0. [return]
If you'd like to read more about the whole thing, drop me a line. [return]