reader 3.15 released – Retry-After
November 2024 ∙ four minute read ∙
Hi there!
I'm happy to announce version 3.15 of reader, a Python feed reader library.
What's new? #
Here are the highlights since reader 3.13.
Retry-After #
Now that it supports scheduled updates, reader can honor the Retry-After HTTP header sent with 429 Too Many Requests or 503 Service Unavailable responses.
Adding this required an extensive rework of the parser internal API, but I'd say it was worth it, since we're getting quite close to it becoming stable.
Next up in HTTP compliance is to do more on behalf of the user: bump the update interval on repeated throttling, and handle gone and redirected feeds accordingly.
Faster tag filters, feed slugs #
OR-only tag filters like get_feeds(tags=[['one', 'two']]) now use an index.
This is useful for maintaining a reverse mapping to feeds/entries, like the feed slugs recipe does to add support for user-defined short URLs:
>>> url = 'https://death.andgravity.com/_feed/index.xml'
>>> reader.set_feed_slug(url, 'andgravity')
>>> reader.get_feed_by_slug('andgravity')
Feed(url='https://death.andgravity.com/_feed/index.xml', ...)
(Interested in adopting this recipe as a real plugin? Submit a pull request!)
enclosure_tags improvements #
The enclosure_tags plugin fixes ID3 tags for MP3 enclosures like podcasts.
I've changed the implementation to rewrite tags on the fly, instead of downloading the entire file, rewriting tags, and then sending it to the user; this should allow browsers to display accurate download progress.
Some other, smaller improvements:
- Set genre to Podcast if the feed has any tag containing "podcast".
- Prefer feed user title to feed title if available.
- Use feed title as artist, instead of author.
Using the installed feedparser #
Because feedparser makes PyPI releases at a lower cadence,
reader has been using a vendored version of feedparser's develop branch
for some time.
It is now possible to opt out of this behavior
and make reader use the installed feedparser package.
Python versions #
reader 3.14 (released back in July) adds support for Python 3.13.
Upcoming changes #
Replacing Requests with HTTPX #
reader relies on Requests to retrieve feeds from the internet;
among others, it replaces feedparser's use of urllib
to make it easier to write plugins.
However, Requests has a few issues that may never get fixed because it is in a feature-freeze – mainly the lack of default timeouts, underpowered response hooks, and no request hooks, all of which I had to work around in reader code.
So, I've been looking into using HTTPX instead.
Some reasons to use HTTPX:
- largely Requests-compatible API and feature set
- while the ecosystem is probably not comparable, it is actively maintained, popular enough, and the basics (mocking, auth) are there
- strict timeouts by default (and more kinds than Requests)
- request/response hooks
- URL normalization (needed by the parser)
Bad reasons to move away from Requests:
- lack of async support – I have no plan to use async in reader at this point
- lack of HTTP/2 support – coming soon in urllib3 (and by extension, Requests?); also, reader makes rare requests to many different hosts, I'm not sure it would benefit all that much from HTTP/2
- lack of Brotli/Zstandard compresson support – urllib3 already supports them
Reasons to not move to HTTPX:
- not 1.0 yet (but coming soon)
- not as battle-tested as Requests (but can use urllib3 as transport)
So, when is this happening? Nothing's actually burning, so soon™, but not that soon; watch #360 if you're interested in this.
That's it for now. For more details, see the full changelog.
Want to contribute? Check out the docs and the roadmap.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
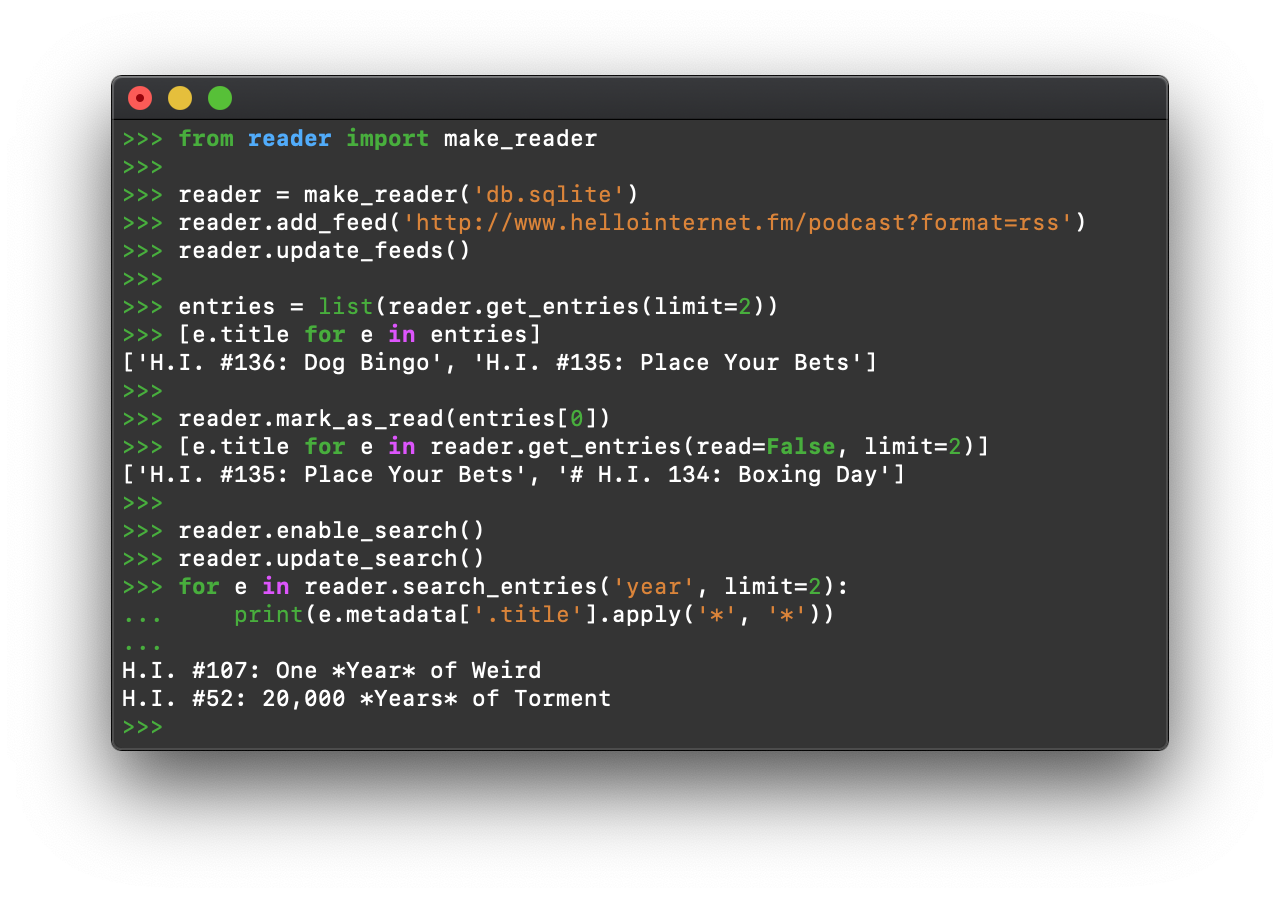 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.