reader 3.22 released – new web app
April 2026 ∙ four minute read ∙
Hi there!
I'm happy to announce version 3.22 of reader, a Python feed reader library.
What's new? #
Here are the highlights since reader 3.20.
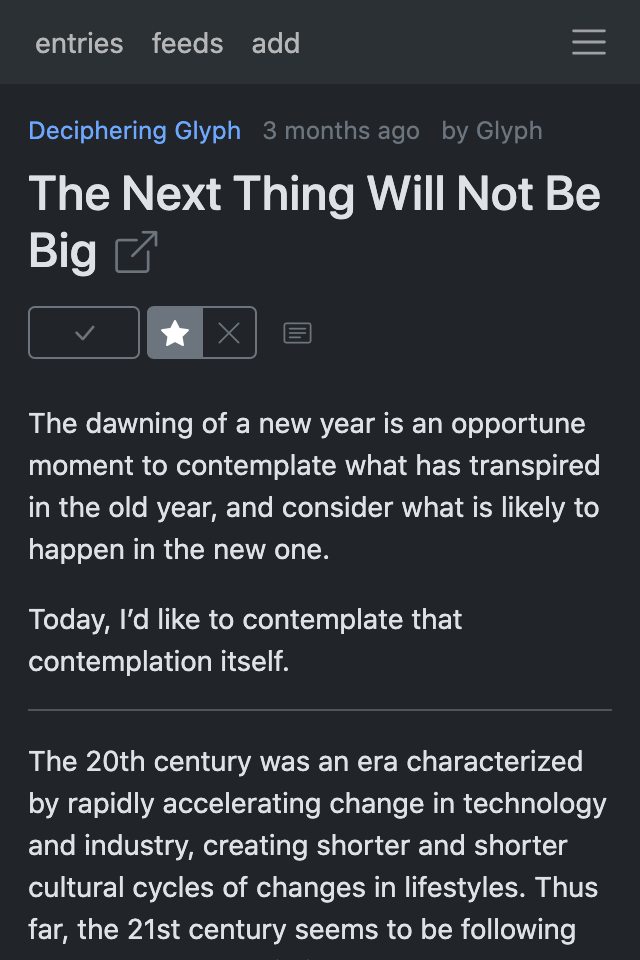
New feed reader web app #
The new web application is done! Features include:
- add / list / filter / delete feeds
- list / filter articles
- mark articles as read / (un)important
- article view
- custom feed titles
- dark mode
In the next releases, I'll be adding back features already present in the legacy web app, stuff like full-text search, tags, read time, MP3 tag fixing, and more.
This is building towards a hosted version of reader, which should take the pain out of self-hosting, while still leaving it as an option; more to follow soon™. (Meanwhile, if this sounds like something you'd like to use, get in touch.)
For now, here are some screenshots:
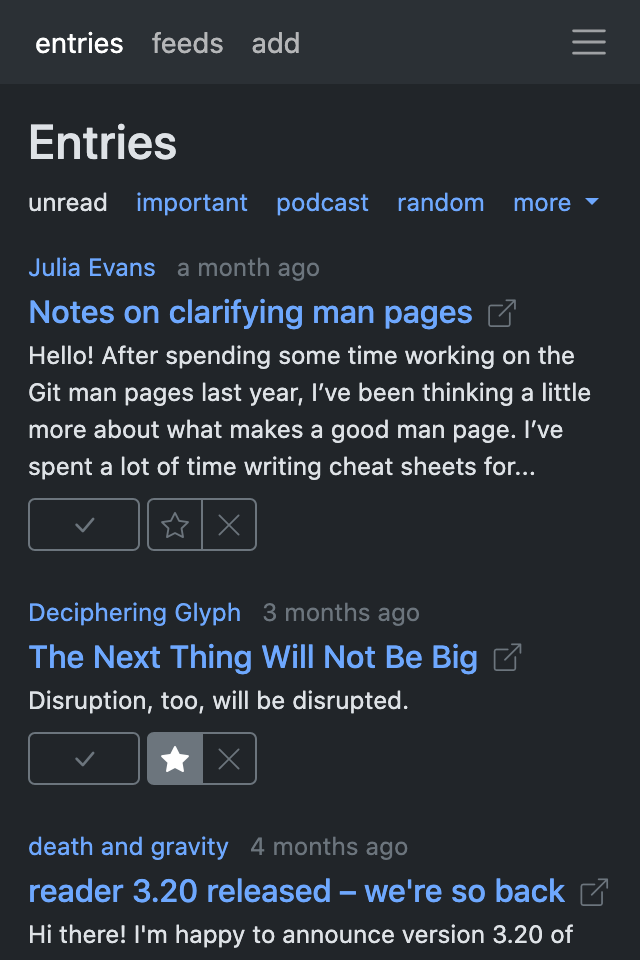
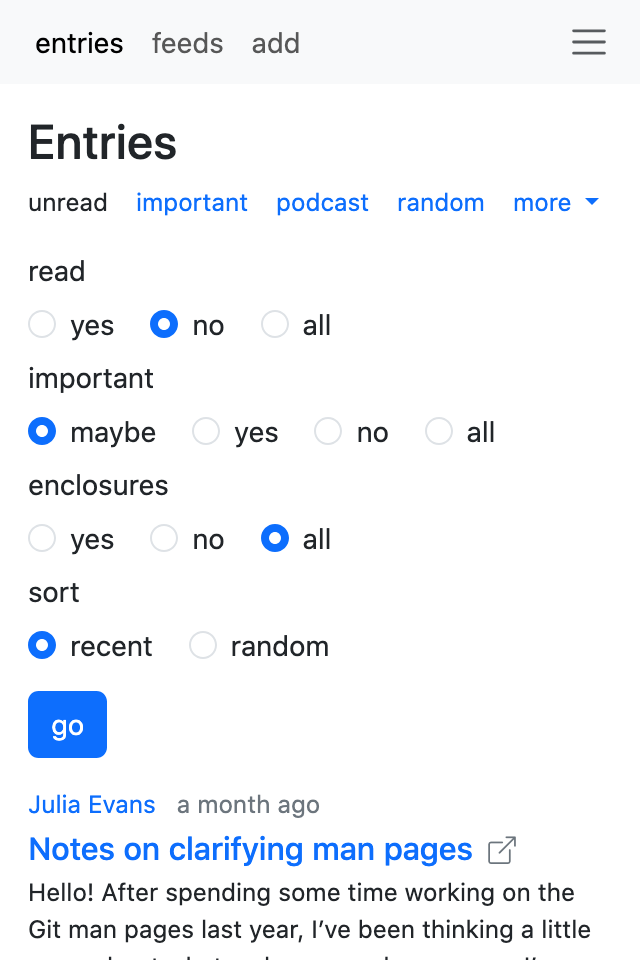
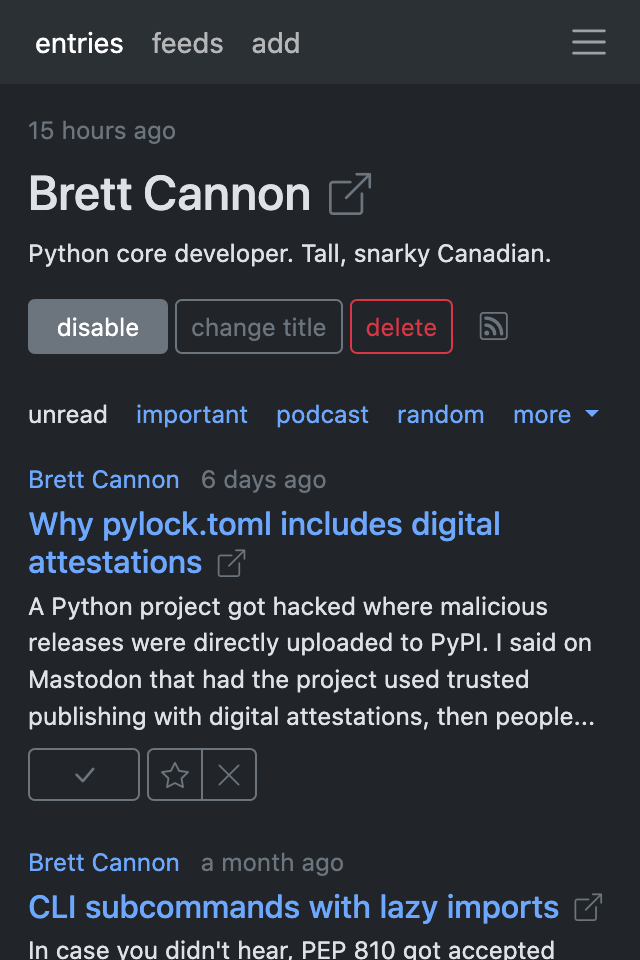
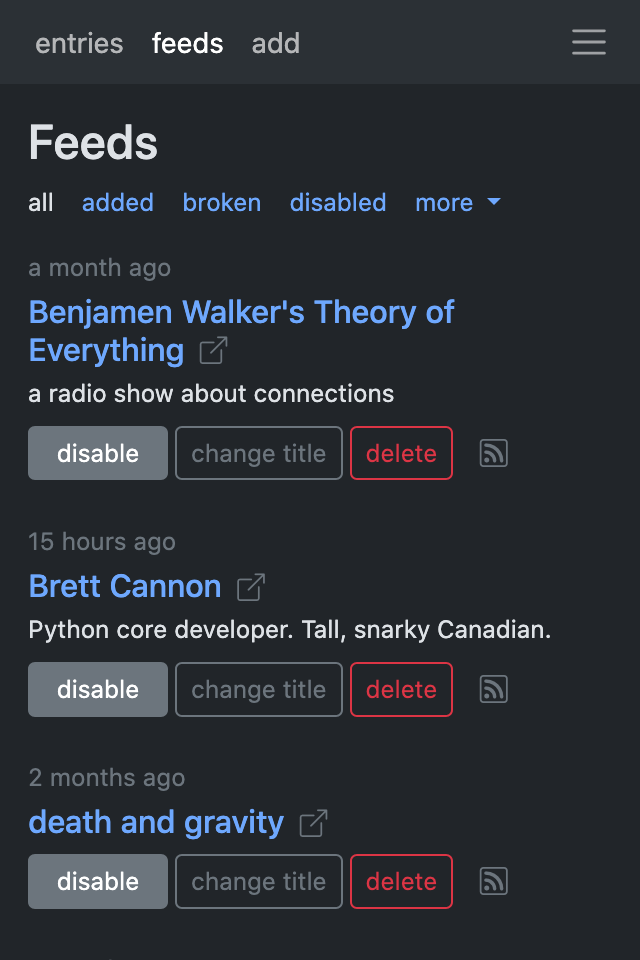

Config and plugin loading #
Part of the hosted reader work, I've unified how configuration and plugins are loaded across make_reader(), the command-line interface, and the web app, by using Click to parse and validate configuration (it's not as wrong as it sounds, I promise).
As a consequence, the config file format changed from YAML to TOML and follows the shape of the CLI, and a few commands and environment variables were renamed; no other breaking changes are expected in the foreseeable future.
Scheduled updates by default #
Both update_feeds() and the CLI now limit how often feeds get updated by default; while this is a minor compatibility break, the previous behavior was arguably a bug – doing the right thing should not be opt-in.
Also, reader now honors the Cache-Control max-age and Expires HTTP headers when updating feeds, in addition to Retry-After.
AI contributions #
Finally, reader now has an AI contributions policy; tl;dr: they are banned, for now.
The reasoning is two-fold. First, after a few low-effort contributions, I decided I don't have time for this. Second, there are various issues surrounding LLMs I don't want to bother with; for more details, see the Servo, CPython, and LLVM policies.
I am open to revisiting this later (I'll do so on my own, though, thank you).
That's it for now. For more details, see the full changelog.
Want to contribute? Check out the docs and the roadmap.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies