reader 3.20 released – we're so back
November 2025 ∙ five minute read ∙
Hi there!
I'm happy to announce version 3.20 of reader, a Python feed reader library.
What's new? #
Here are the highlights since reader 3.16.
Web app re-design #
Earlier this year, I started a web app re-design based on htmx and Bootstrap. I only had time for the main page, but it turned out pretty nice, and I've been using it ever since. What is new is that I now have free time and some plans; watch this space.
Here are some screenshots; it's not much, but it's honest work:
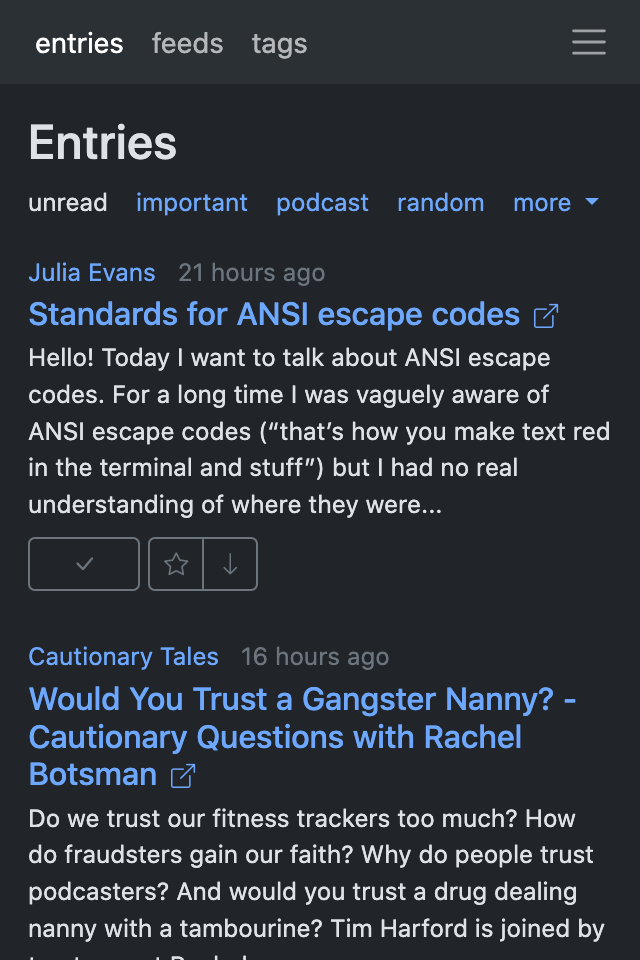
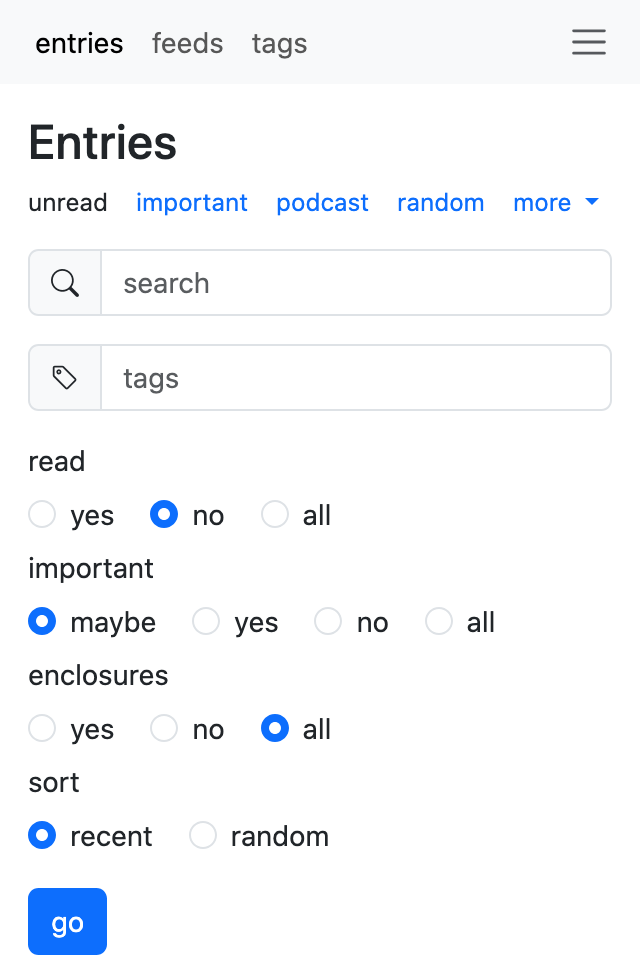
htmx? ugh, how original
Unsurprisingly, htmx is perfect for this kind of application. As CEO of htmx, I can confirm that all the allegations are true – it is indeed a pleasure to use, not to mention a huge improvement over my home-grown, half-assed JavaScript forms framework.
isn't Bootstrap from like 2010 or something? also, how original
I've tried many modern popular CSS frameworks (since forgotten, for my own sanity), and it turns out tab-navigable form controls are a hard, unsolved problem in 2025. Thankfully, if you're willing to time travel (to the future, surely!), Bootstrap comes with excellent documentation, built-in accessibility, and a comprehensive component library.
Entry deduplication #
I may have accidentally rewritten the entry_dedupe plugin. 😅
Sometimes, the id of some or all the entries in a feed changes (e.g. from
example.com/123toexample.com/entry-title), causing each entry to appear twice. entry_dedupe fixes this by copying user attributes to the new entry and deleting the old one.
What started as a quick and dirty plugin now has:
- lots of new, data-driven heuristics to find potential duplicates
- by title (had this one already)
- by link
- by published timestamp
- by title with common prefixes removed
- better approximate content matching
- an extensive test suite
- extensive internal documentation (like this)
That last one is pretty important: the old logic was data-driven too, but because I didn't document my entire reasoning, I wasted more time than I'd like to admit on a useless title similarity heuristic. It's a trope that you should write code such that others can understand it, and "others" includes you six months from now; I don't know about six months, but four years will definitely do it. (If that sounds like an interesting story and you'd like to hear more, drop me a line.)
It's not all bad, though –
a side-effect of better content matching
is that image alt and title attributes
are also included in the full-text search index now,
so you can search xkcd comics by title text.
Project infrastructure #
I've taken some time to modernize the project infrastructure; stuff like:
- Use GitHub Actions to publish releases to PyPI.
- Use dependency groups instead of extras for development dependencies.
- Rewrite contributor documentation and run.sh to optimize for readability.
(I'll admit the uv hype is quite strong, but the vanilla tooling seems fine, for now.)
Read-only Reader #
It's now possible to prevent write operations on a Reader object
through the read_only make_reader() argument.
Thanks to Roman Milko for the pull request!
Python versions #
reader 3.17 added support for PyPy 3.11.
reader 3.18 dropped support for Python 3.10.
reader 3.19 added support for Python 3.14.
That's it for now. For more details, see the full changelog.
Want to contribute? Check out the docs and the roadmap.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
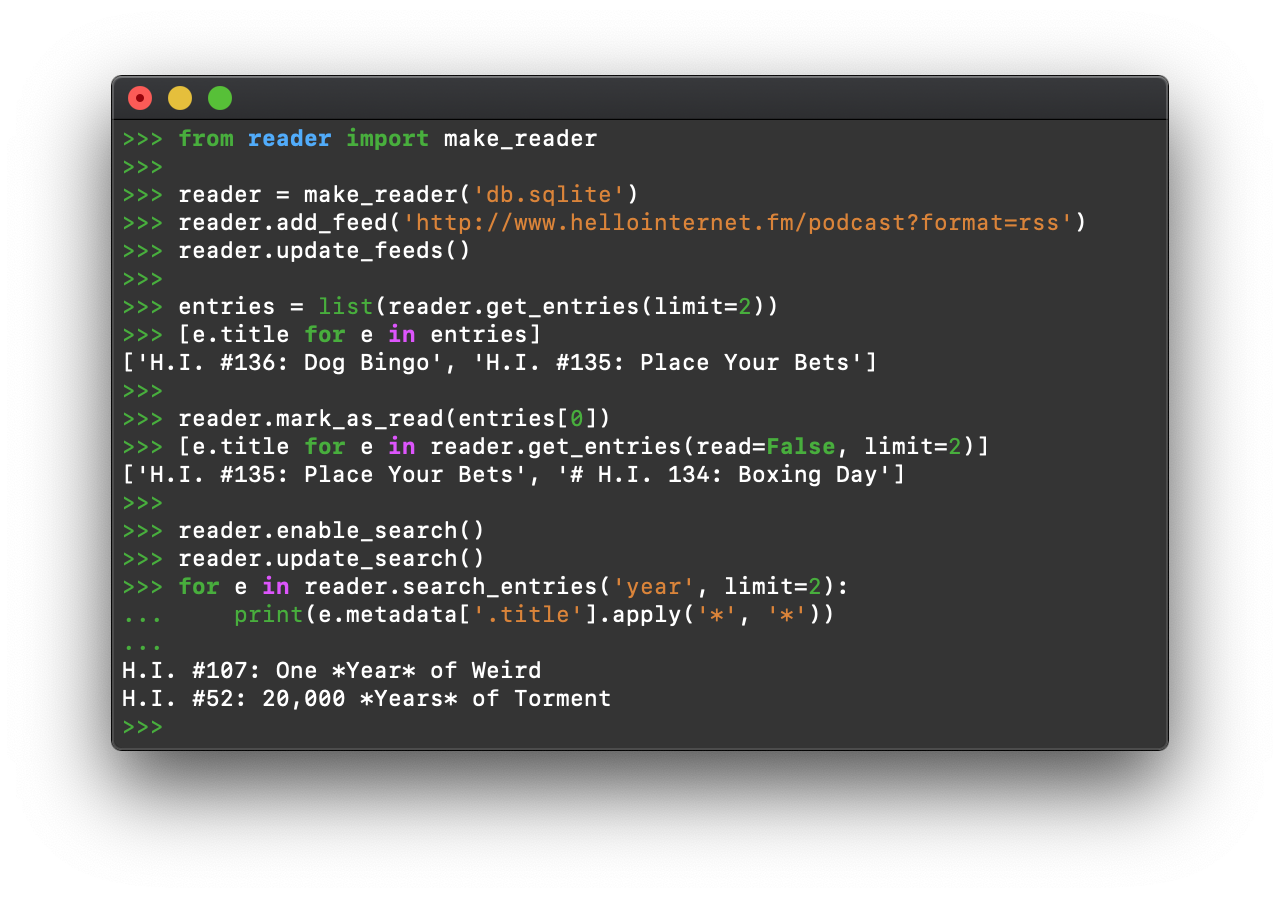 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.