reader 3.12 released – split search index
March 2024 ∙ four minute read ∙
Hi there!
I'm happy to announce version 3.12 of reader, a Python feed reader library.
What's new? #
Here are the highlights since reader 3.10.
Split the search index into a separate database #
The full-text search index can get almost as large as the actual data, so I've split it into a separate, attached database, which allows backing up only the main database.
(I stole this idea from One process programming notes (with Go and SQLite).)
Change tracking internal API #
To support the search index split, Storage got a change tracking API that allows search implementations to keep in sync with text content changes.
This is a first step towards search backends that aren't tightly-coupled to a storage. For example, the SQLite storage uses its FTS5 extension for search, and a PostgreSQL storage can use its own native support; the new API allows either storage to use something like Elasticsearch. (There's still no good way for search to filter/sort results without storage cooperation, so more work is needed here.)
Also, it lays some of the groundwork for searchable tag values by having tag support already built into the API.
Here's how change tracking works (long version):
- Each entry has a 16 byte random sequence that changes when its text changes.
- Sequence changes get recorded and are available through the API.
- Search
update()processes pending changes and marks them as done.
While simple on the surface, this prevents a lot of potential concurrency issues that needed special handling before. For example, what if an entry changes during pre-processing, before it is added to the search index? You could use a transaction, but this may keep the database locked for too long. Also, what about search backends where you don't have transactions?
I used Hypothesis and property-based testing to validate the model, so I'm ~99% sure it is correct. A real model checker like TLA+ or Alloy may have been a better tool for it, but I don't know how to use one at this point.
Filter by entry tags #
It is now possible to filter entries by entry tags:
get_entries(tags=['tag']).
I did this to see how it would look to implement the has_enclosures get_entries() argument as a plugin (it is possible, but not really worth it).
SQLite storage improvements #
As part of a bigger storage refactoring, I made a few small improvements:
- Enable write-ahead logging only once, when the database is created.
- Vacuum the main database after migrations.
- Require at least SQLite 3.18, since it was required by update_search() anyway.
Python versions #
reader 3.11 (released back in December) adds support for Python 3.12.
That's it for now. For more details, see the full changelog.
Want to contribute? Check out the docs and the roadmap.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
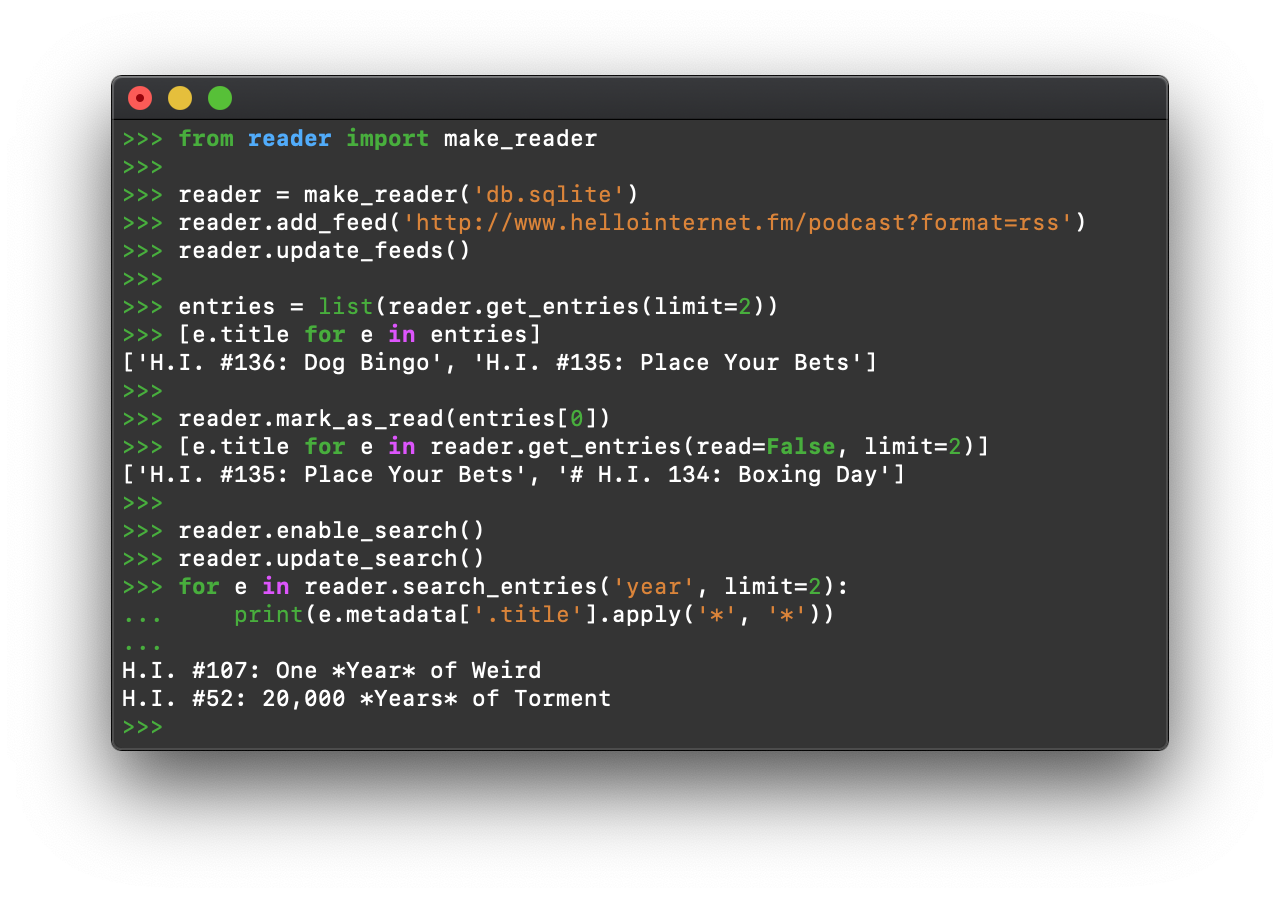 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies
Why make your own feed reader? #
So you can:
- have full control over your data
- control what features it has or doesn't have
- decide how much you pay for it
- make sure it doesn't get closed while you're still using it
- really, it's easier than you think
Obviously, this may not be your cup of tea, but if it is, reader can help.