reader 3.26 released – discovery, exports, demo
June 2026 ∙ three minute read ∙
Hi there!
I'm happy to announce version 3.26 of reader, a Python feed reader library.
What's new? #
Here are the highlights since reader 3.24.
Feed autodiscovery #
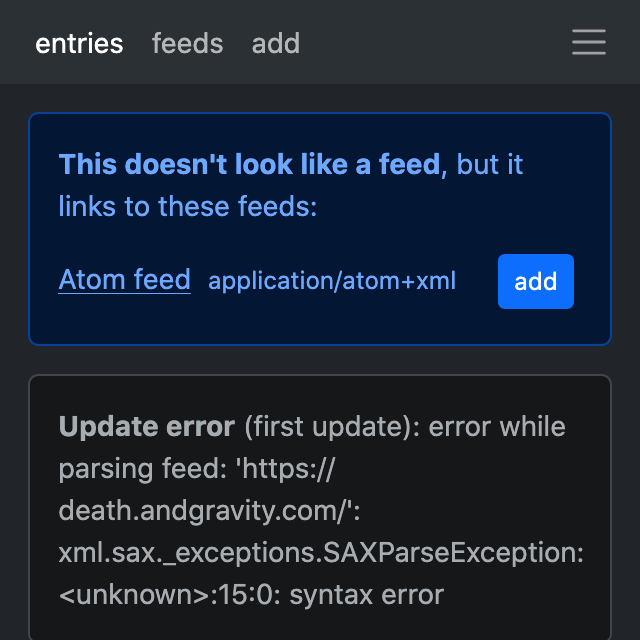
reader now discovers feeds automatically – instead of searching for feed links, just add the website URL, and the web app will suggest any feeds it finds.
Behind the scenes, this is enabled by the autodiscover plugin, which stores discovered feeds in a feed tag, so you can use it without the web app, or even without reader. For a short related rant about standards, check out this Bluesky thread (there are cats!).
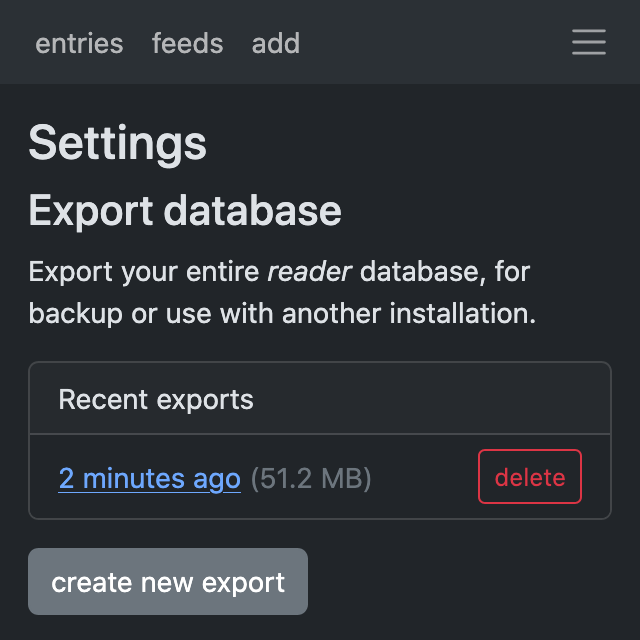
Database exports #
This is an optional feature that I really wanted in the hosted reader MVP – it should be possible to get all your data out, not just lists of feeds and read / starred articles.
So yeah, now you can download a copy of your entire database from the web app, which means you can always migrate to another reader installation. (If you're using reader locally or self-hosting, the command might be handy for backups.)
Hosted reader status update #
Speaking of, did I tell you I'm working on a hosted version of reader? :D
Background: Why another feed reader web app?, Why not just self-host it?
Public demo #
Another thing I wanted for the MVP was a demo (no login needed):
Go forth and click all the things! (it's read-only, nothing should break™)
OK, so what now? #
This is what is finished so far:
- multi-user version of the web app
- authentication via email
- infrastructure deployments using pyinfra
- multi-user feed updates
- context-sensitive help
- (new) public demo
So just launch the damn thing already:
- set up a landing page
- give it a good name
- publish a launch announcement + roadmap
Meanwhile, if this sounds like something you'd like to use, get in touch.
That's it for now. For more details, see the full changelog.
Want to contribute? Check out the docs and the roadmap.
Learned something new today? Share it with others, it really helps!
What is reader? #
reader takes care of the core functionality required by a feed reader, so you can focus on what makes yours different.
 reader allows you to:
reader allows you to:
- retrieve, store, and manage Atom, RSS, and JSON feeds
- mark articles as read or important
- add arbitrary tags/metadata to feeds and articles
- filter feeds and articles
- full-text search articles
- get statistics on feed and user activity
- import / export feeds as OPML
- automatically discover feeds in web pages
- write plugins to extend its functionality
...all these with:
- a stable, clearly documented API
- excellent test coverage
- fully typed Python
To find out more, check out the GitHub repo and the docs, or give the tutorial a try.
Why use a feed reader library? #
Have you been unhappy with existing feed readers and wanted to make your own, but:
- never knew where to start?
- it seemed like too much work?
- you don't like writing backend code?
Are you already working with feedparser, but:
- want an easier way to store, filter, sort and search feeds and entries?
- want to get back type-annotated objects instead of dicts?
- want to restrict or deny file-system access?
- want to change the way feeds are retrieved by using Requests?
- want to also support JSON Feed?
- want to support custom information sources?
... while still supporting all the feed types feedparser does?
If you answered yes to any of the above, reader can help.
The reader philosophy #
- reader is a library
- reader is for the long term
- reader is extensible
- reader is stable (within reason)
- reader is simple to use; API matters
- reader features work well together
- reader is tested
- reader is documented
- reader has minimal dependencies